
AWSの新認定試験 AWS Certified AI Practitioner (AIF) 勉強会を実施したのでその内容をまとめました【その1:AI/ML一般知識】
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
先日社内向けに新しい認定試験、AWS Certified AI Practitioner(AIF)の勉強会を開催しましたので、その内容に関する記事です。
勉強会は以下の公式の試験ガイドを元に内容について深堀しました。
弊社ブログでも試験について以下にまとめられています。
勉強会に使用したスライドは以下です。(実際にはAI/ML一般知識の部分は社外公開用に加筆しました)
本ブログでも3回に分けてこちらの内容をご紹介します。
- AIF勉強会を実施したのでその内容をまとめました【その1:AI/ML一般知識】 ※本記事※
- AIF勉強会を実施したのでその内容をまとめました【その2:生成AI+Bedrock】
- AIF勉強会を実施したのでその内容をまとめました【その3:SageMaker+その他】
第1回目では、「AI/ML一般知識」についてです。「AI/ML一般知識」については理解しておくとその後のサービスの理解がしやすくなりますので、少し試験に必要な部分よりも手厚めに深堀をしています。
※追記※:おもに第2回目の内容について先日10/9の登壇で簡単にお話いたしました。
AIとは
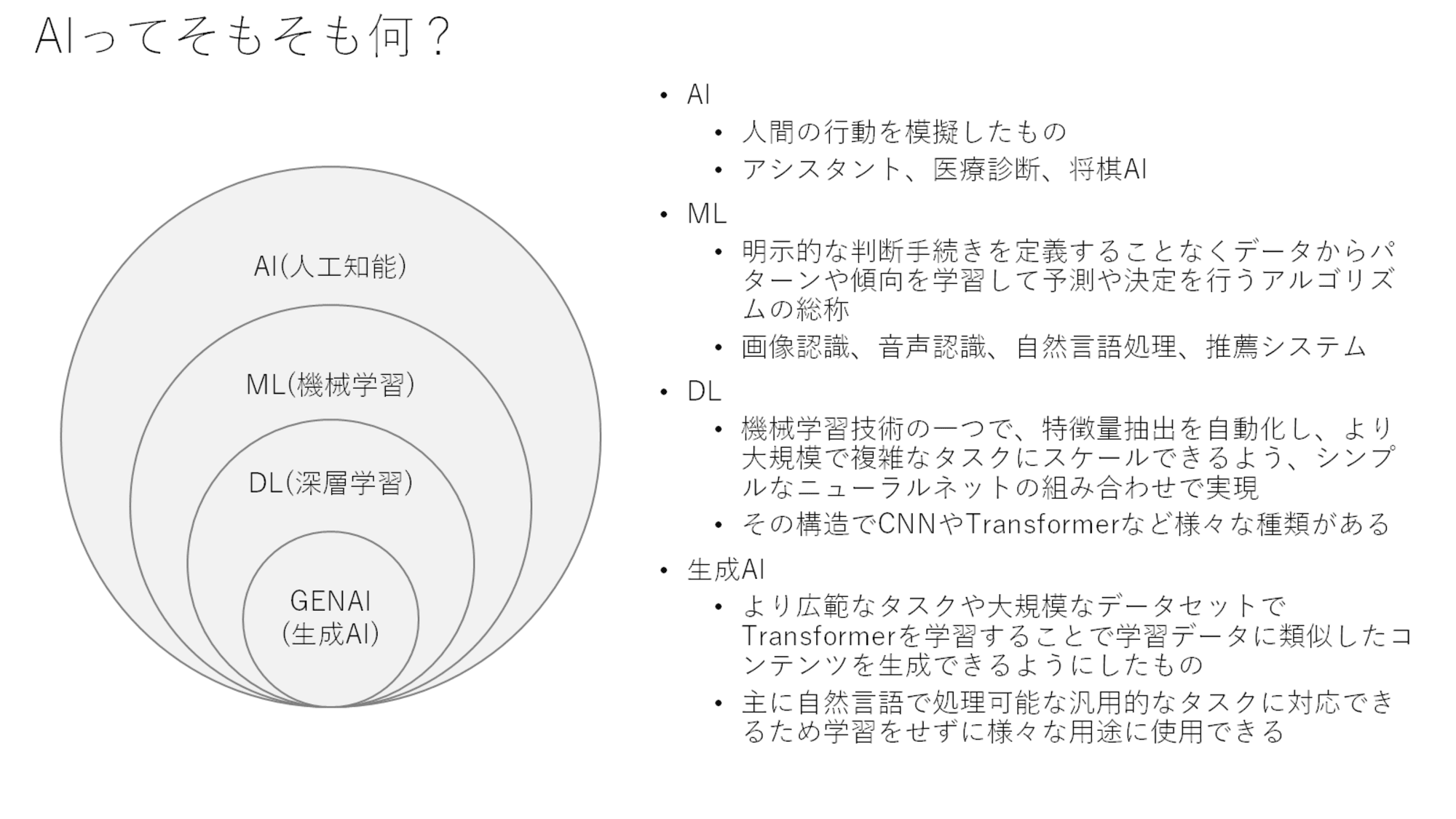
AIとは何か、機械学習(ML)や深層学習(Deep Learning)、生成AIの説明をしながら説明しています。
図的にはきれいな包含関係を持っているように描いていますが、標準化された技術用語の話はしていないので、あくまでイメージの一例として理解ください。(ここに違和感を感じる人は、この説明をしなくても理解されているとおもいますので。。。)
また最近は、AI/MLとひとくくりの用語として表現されることもあります。
MLパイプライン
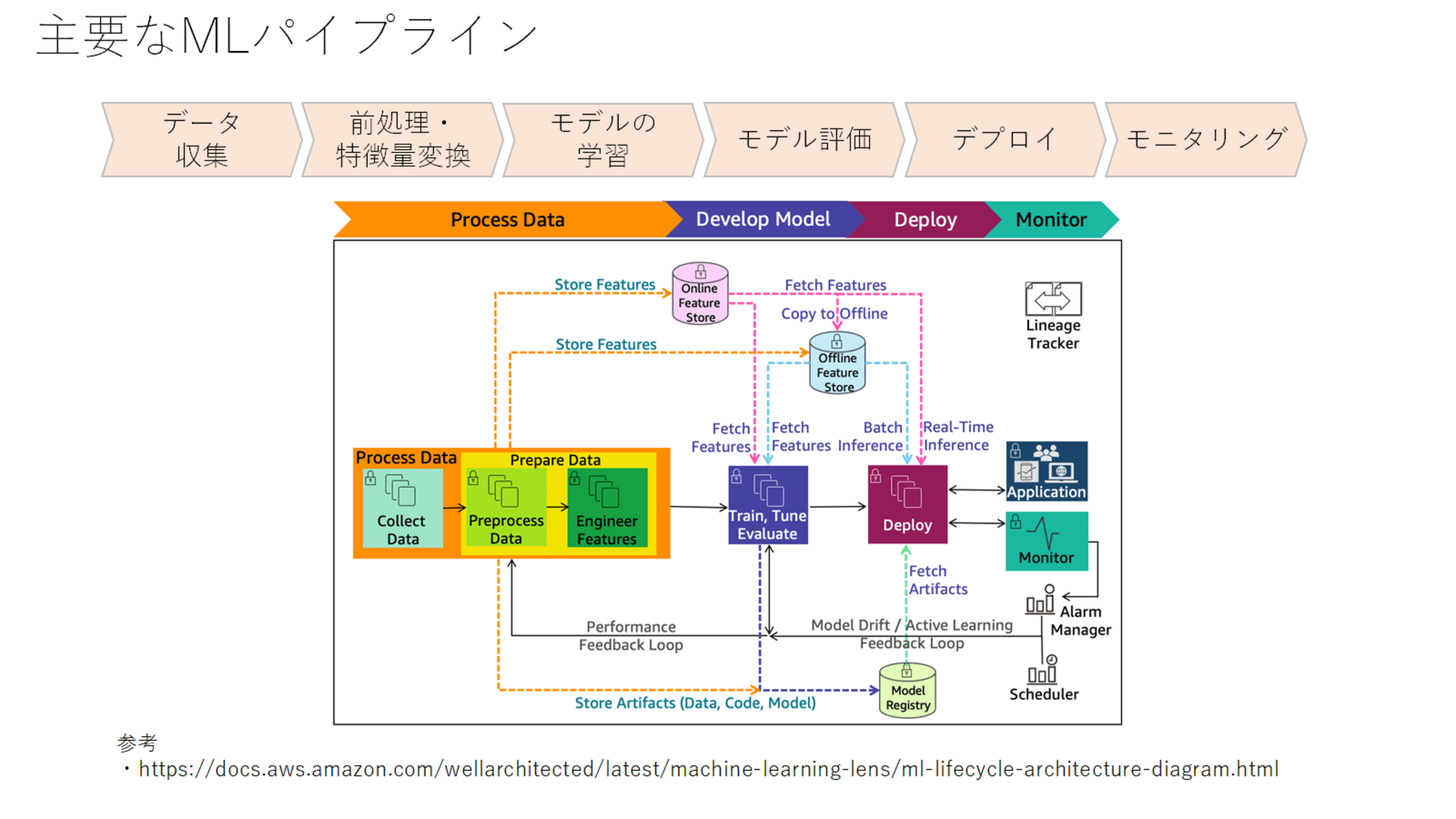
AWSもAWS Well-Architedted Frameworkとして、Machine Learning Lensを公開しています。
この中に記載されているMLパイプラインが上記の図になります。
詳細はMachine Learning Lensで理解できると思いますが、プロセスとしては以下の6つのプロセスから構成されています。
- データ収集
- データ前処理・特徴量変換
- モデル学習
- モデル評価
- デプロイ
- モニタリング
データ収集はとても重要ですが、技術的な話というよりは正常なデータを必要量集めるという観点が重要になってきます。
データの前処理や特徴量変換も後段のモデルによってはかなり重要な要素です。前処理は欠損値や重複の除去やデータ型の変換、標準化、数値へのエンコードなどが含まれます。特徴量変換も重複する部分はあるのですが、複数の特徴量を組み合わせたり、次元削減なども含まれます。
モデル学習以降については、さらに別スライドで詳しく説明していきます。
深層学習の用語
ここから深層学習の用語について説明していきます。(実際には深層学習にとどまらない機械学習の話も含まれますがご容赦ください)
データの分割
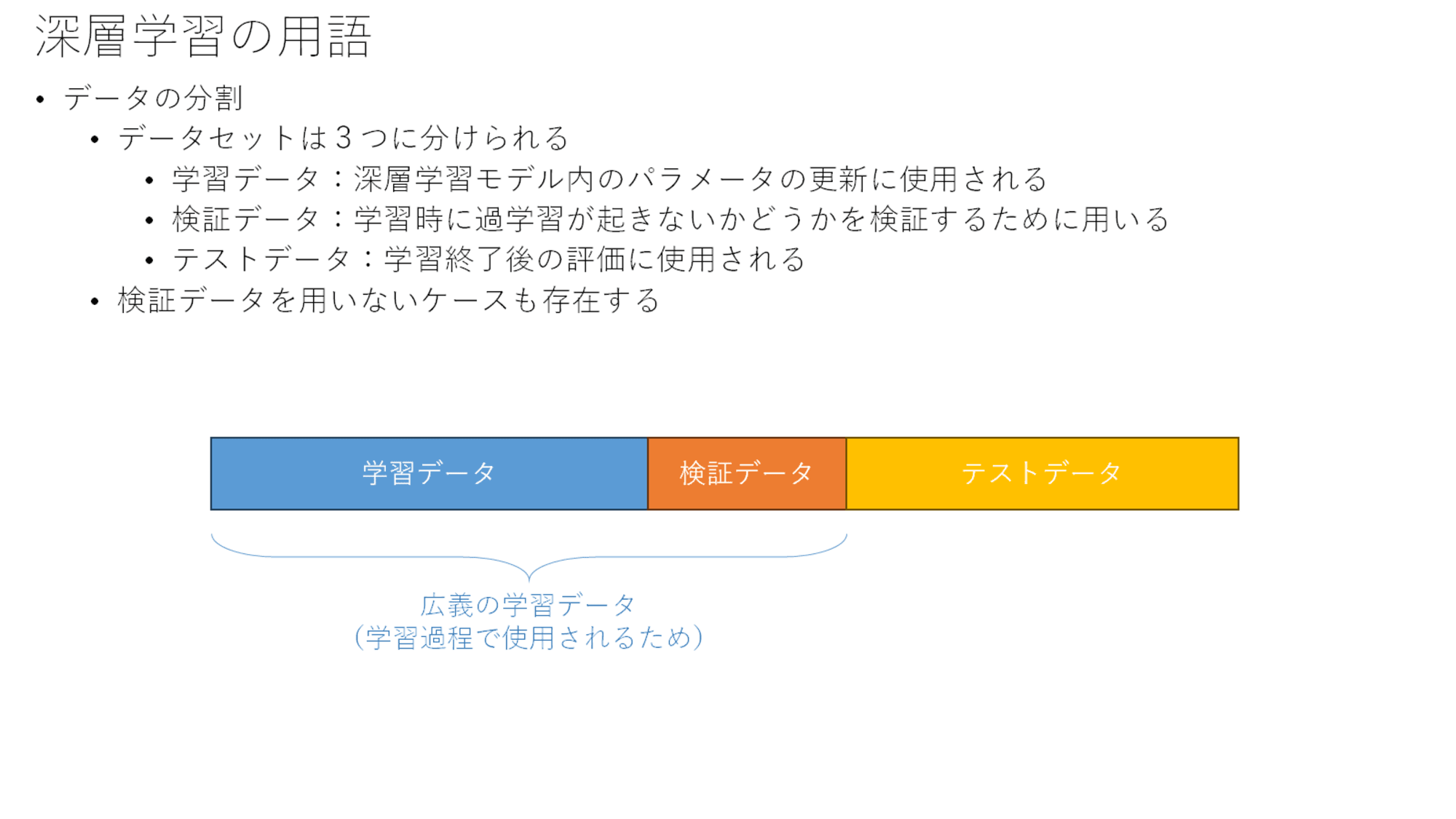
図に記載のように3つに分割して考えることが多いです。
最初は検証データとテストデータの違いが理解しづらいのですが、モデル学習を適切に制御する過程で、検証データが必要になるケースがあります(過学習が発生しそうになったら学習を止める、など)。
特に深層学習の場合、モデル自体の表現力が高いため、このような制御が広く用いられているようです。
ただしこの学習過程の中で、検証データによる評価は通常何回も繰り返されます。そのため最終的なモデルが、今度はこの検証データに対しても過学習な状態となることがあります。そのため、最終的な評価としてはテストデータを使用して評価が必要となってきます。
ここまでのロジックで気づいた方もいらっしゃるかもしれませんが、テストデータも何回も評価をすると結局テストデータについても過学習になると考えられます。そうするとまた新しいデータを集める必要が出てくるという感じです。
これらの問題は、機械学習のコンペなどでは通常うまく設計されており、コンペ開催中のリーダーボードに使われるデータセットと、最終的に使用されるデータセットは分けて準備されて、後者は前者よりも大規模に準備され、かつ後者は最後の1回だけでしようされるような仕組みとなっているようです。
ちょっと余談にそれてしまいましたが、深層学習の場合、通常は3つにわけることが多いということをご理解いただいておけば良いかと思います。
学習過程とミニバッチとエポック数
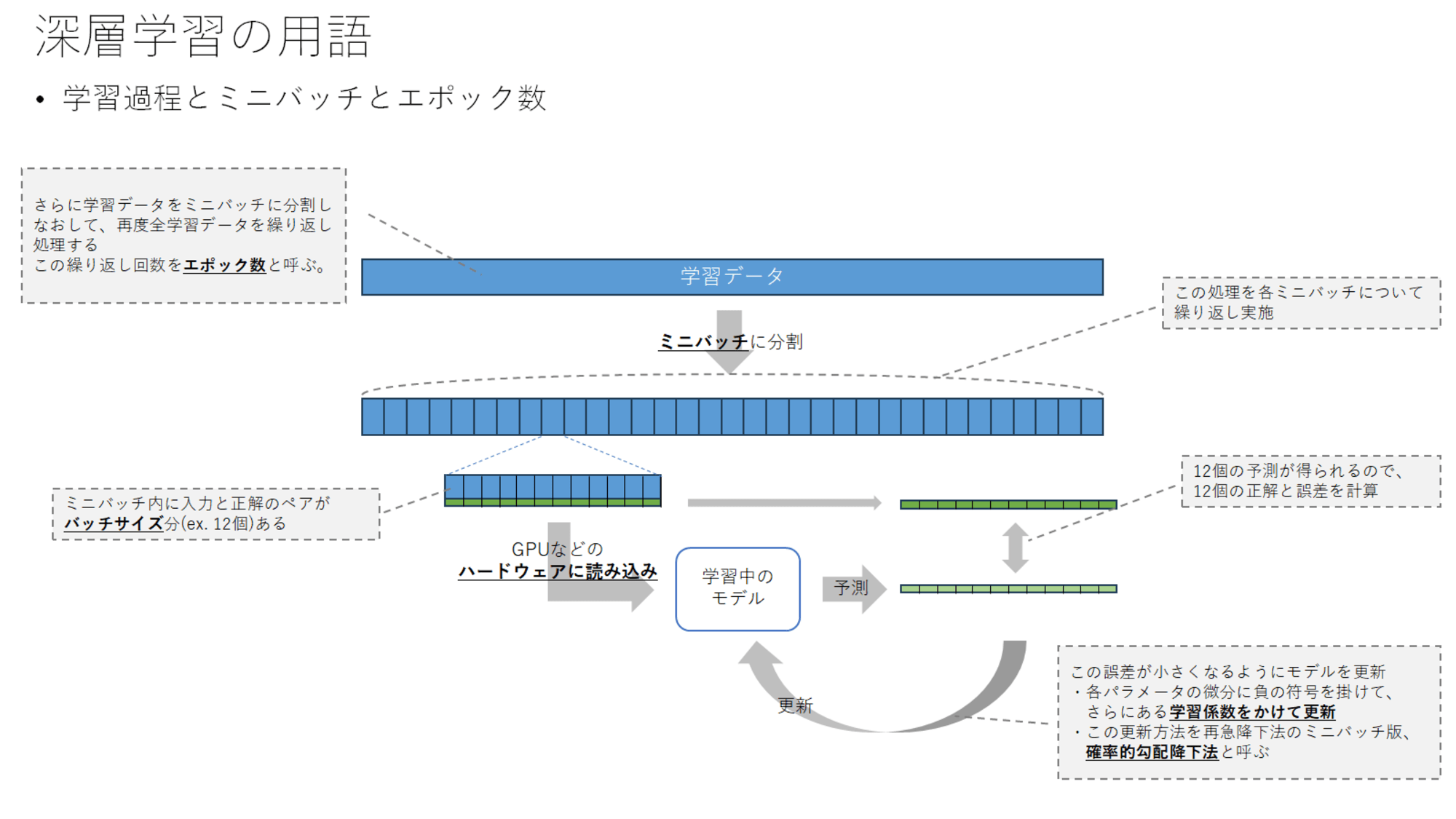
そして実際に学習データをどのように使っているか、用語を説明しつつ上記の図で説明しています。
学習データは通常、ミニバッチに分割します。このミニバッチ内に入力(特徴量など)と正解(予測したい値)のペアが複数個存在しているような形となります。このミニバッチのサイズをバッチサイズと呼びます。
学習時は、このミニバッチ単位でGPUなどのハードウェアに読み込みを行って並列処理をします。処理後の予測結果と正解の誤差を計算します。
この誤差が小さくなるように、モデル内のパラメータを更新します。更新方法はミニバッチを使った勾配降下法を用い、各パラメータで誤差を微分して、その微分に学習係数を掛けてパラメータから値を減算します。これにより誤差関数の傾きと反対方向にパラメータを更新することで、誤差が極小になる点に到達するように更新しています。このミニバッチ単位で勾配降下法を使うことを確率的勾配降下法と呼びます。
この処理がミニバッチごとに実行され、一通り処理が終わると再度くりかえされます。この繰り返し回数をエポック数と呼びます。
少し小難しい話になりましたが、学習がうまく行かない場合にバッチサイズや学習係数などのキーワードを理解しておくと頭に入りやすいので説明しています。
学習過程における損失(誤差)について
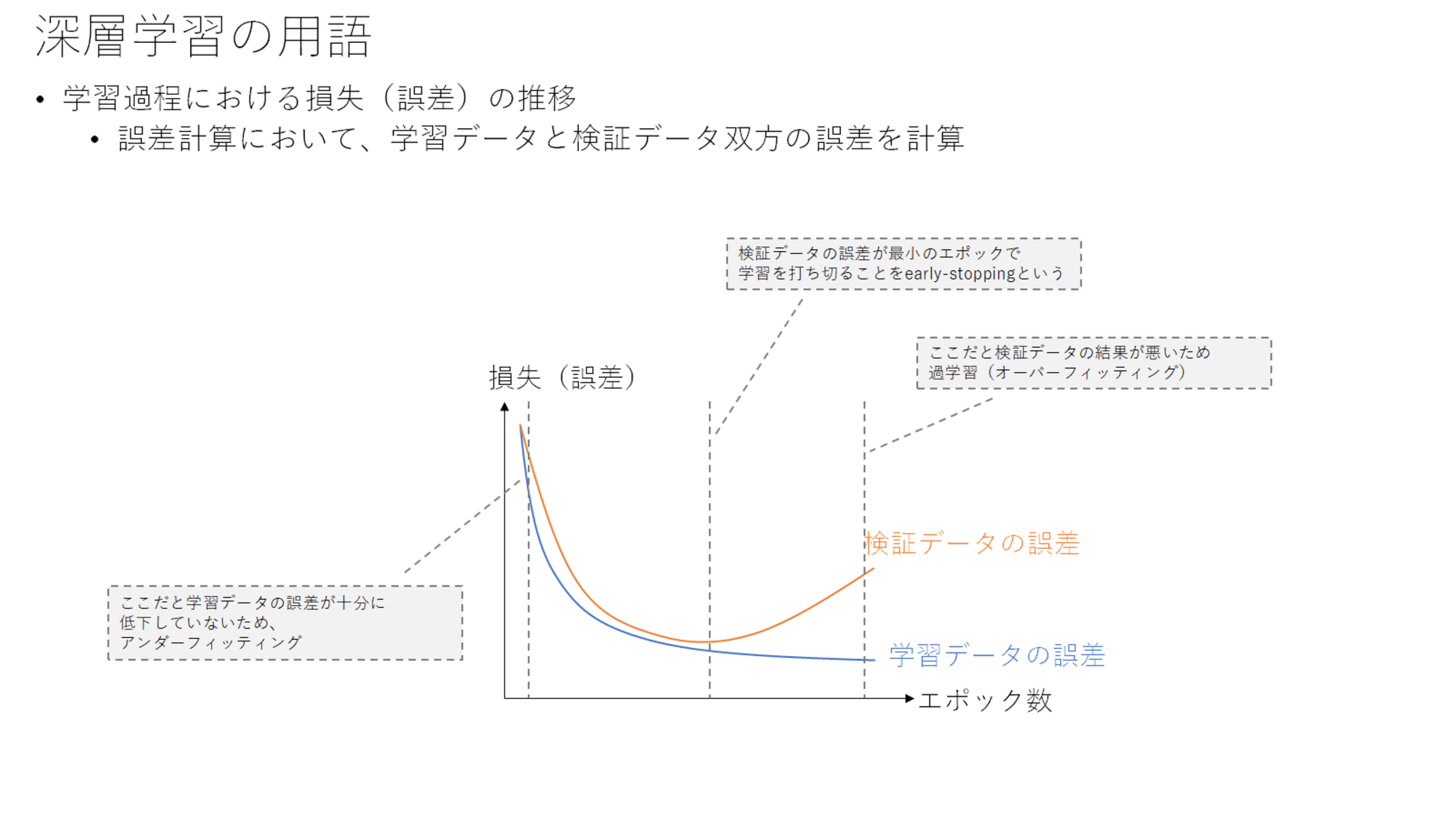
前のスライドはデータの扱いに焦点を当てていましたが、更新による損失の遷移について見てみます。上記は代表的な損失の遷移です。
初期段階では、学習データの損失が十分に下がっていないアンダーフィッティングの状態のため、まだ学習を進める必要があります。
また学習を進めすぎると、検証データの誤差が増えてしまっており、学習データについて過学習となっています。
そのため検証データが最小となる点で学習を打ち切ることが多く、この打ち切ることをearly-stoppingと呼びます。
学習が進まないときのアクション
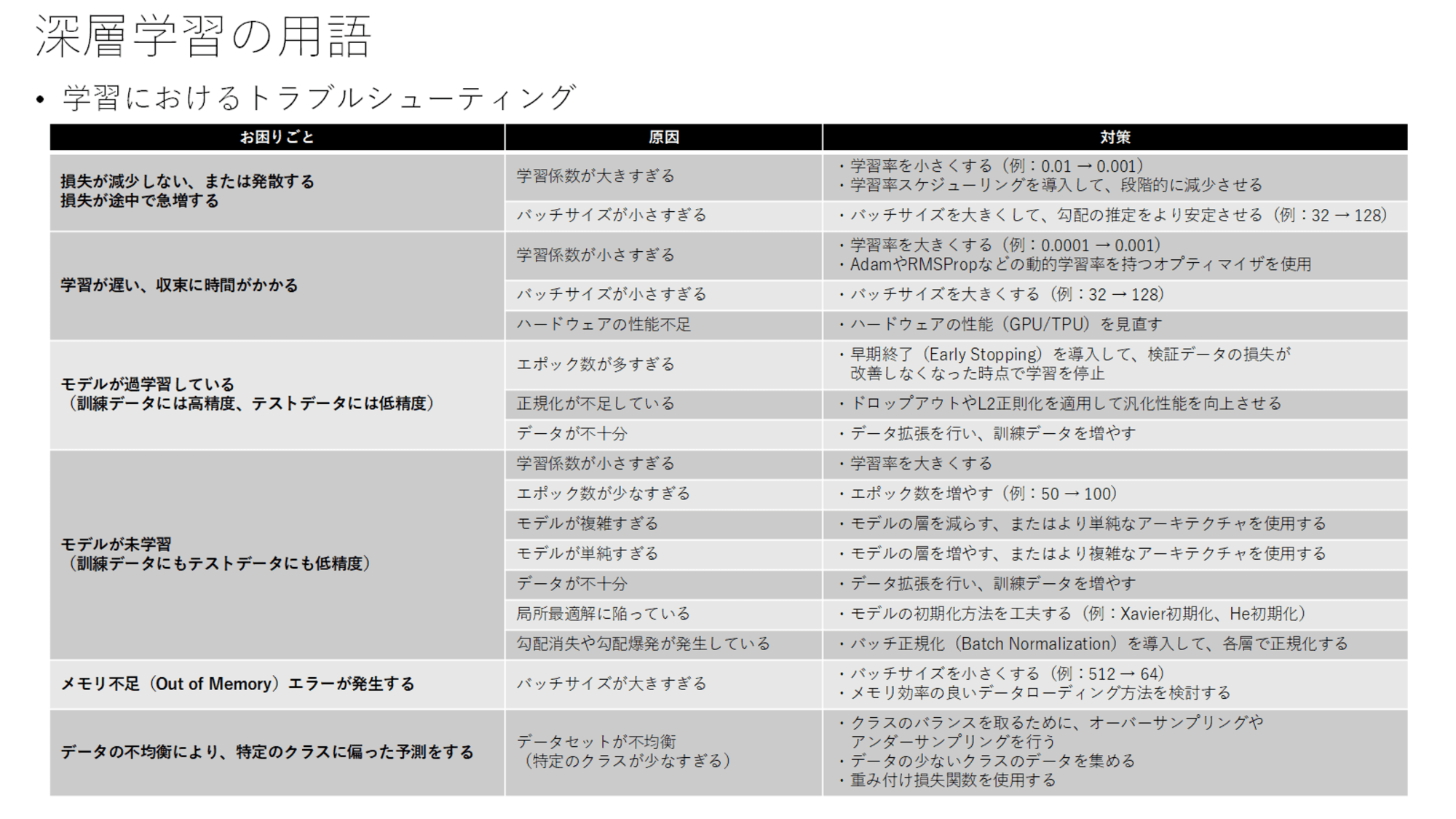
ここまでの用語の説明を踏まえて、学習が進まないときの一般的なアクションを紹介しています。
原因別にみると、学習係数、バッチサイズ、エポック数などの観点で整理ができます。
- 学習係数
- 大きすぎる:損失が減少しない、振動または発散する
- 小さすぎる:学習が遅い、未学習(アンダーフィッティング)となる
- バッチサイズ
- 小さすぎる:損失が減少しない、振動または発散する
- 大きすぎる:メモリ不足エラーとなる
- エポック数
- 少なすぎる:未学習(アンダーフィッティング)となる
- 多すぎる:過学習(オーバーフィッティング)となる
- その他
- 正規化が不足:過学習(オーバーフィッティング)となる
- データが不十分:未学習、過学習双方になりうる
- モデルが複雑すぎる、単純すぎる:未学習(アンダーフィッティング)となる
- ハードウェアの性能不足:学習が遅い
主要なMLモデル
テーブルデータに対するモデル
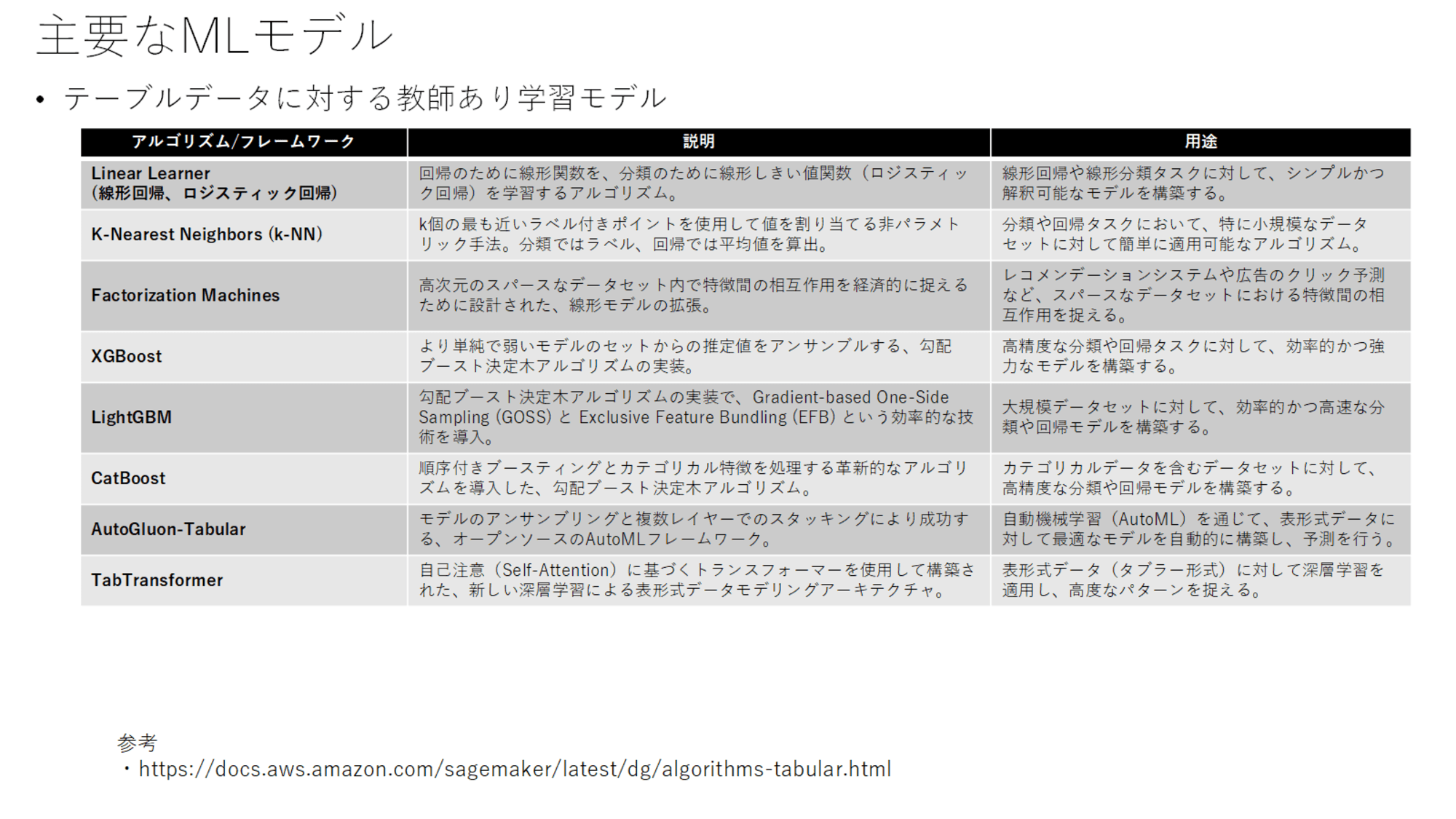
ここまでは深層学習について詳しく見ていきましたが、それ以外のモデルについてもSageMakerのドキュメントを参考に整理しています。
Linear Learnerは回帰タスクの線形回帰と、分類タスク向けのロジスティック回帰を含んでいます。
回帰タスクは連続値を予測するタスクで、分類タスクは猫か犬かどうかを判定する画像分類などのタスクを指しています。
k-近傍法(k-NN)は後述のk-meansと区別して覚えましょう。k-近傍法は分類・回帰タスクに使用します。k-meansは教師なし学習で、クラスタリング(グループ化)に使用されるモデルです。
XGBoostやLightGBM、CatBoostは勾配ブースティング決定木のアルゴリズムです。詳細な差分までは把握していなくても良いと思います。
AutoGluonはAutoMLのフレームワークです。TabTransformerはTransformerでテーブル形式データを処理するためのモデルです。
テキスト分析・時系列分析

これらも以下を参考にまとめています。
各手法がテキスト分析、時系列分析の手法であることを把握しておくと良さそうです。
教師なし学習・画像分析
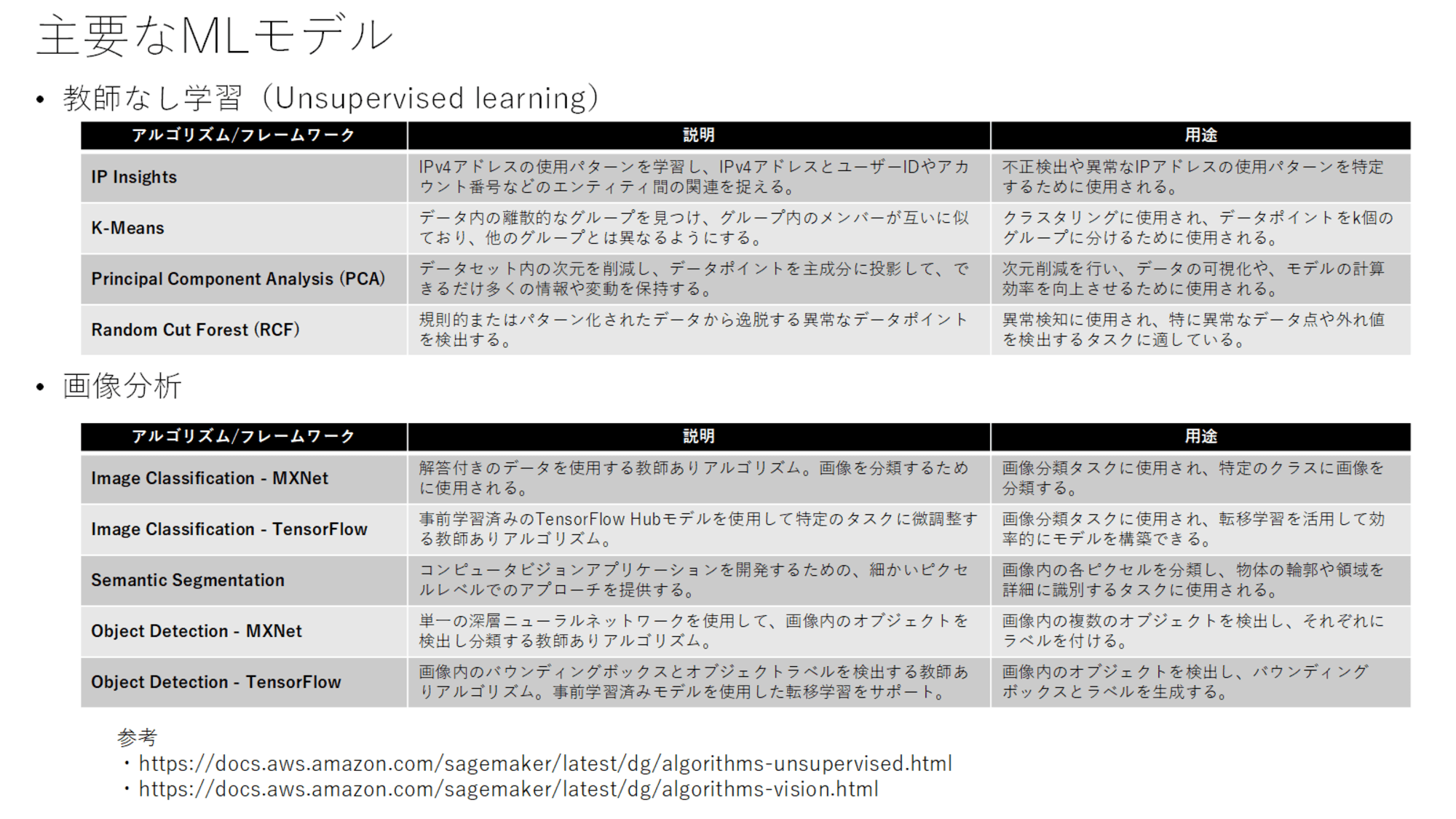
これらも以下を参考にまとめています。
教師なし学習は、IP InsightsとRCFが異常検知に該当し、k-meansがクラスタリング、PCAが次元削減に該当しています。
画像分析は各手法が画像分析の手法であることを把握しておくと良さそうです。
主要なメトリクス
分類問題のメトリクス

次はモデルの評価に使用するメトリクスについてです。以下を参考にまとめています。
recallは検出漏れを避けたい場合に重視する手法で、医療などの分野で重視されます。precisionは検出漏れよりも誤報の少ないことを重視する手法で、スパム検出が該当します。f1スコアはこれらの調和平均です。
accuracyは全体の正確性を重視しますが、クラスに偏りがある場合に、サンプルの多いクラスが重視される指標になるため、その補正がかかったbalanced accuracyというものがあります。
その他のメトリクスもクラス分類に関するものということを理解しておきましょう。
回帰問題のメトリクス

回帰問題についても以下を参考にまとめています。
回帰問題に関するメトリクスということを理解しておきましょう。
時系列予測で使用されるメトリクス

時系列予測のメトリクスは以下を参考にまとめています。
LLMの評価に使用されるメトリクス

メトリクスの最後はLLMの評価に使用されるメトリクスで、以下を参考にまとめています。
バイアスについて

最後にバイアスについて表にまとめています。以下の記事を参考にまとめています。
想起バイアスだけは人間が持つバイアスですが、それ以外は機械学習自体またはモデル作成者がデータの準備段階や評価段階で陥るバイアスとなっています。
まとめ
いかがでしたでしょうか。あと2回にわたってまとめていくのでそちらも参考にされてください。
AIFの試験を受けられる方の参考になれば幸いです。









